Performing Fast Video Rotation in D
I explore how I tackled a problem with video rotation at Loki and demonstrate how it is sometimes necessary to write low-level code to meet a real-time processing deadline
Background
Loki’s initial live streaming client was an Android app developed for the Nexus 5X. Since Loki was meant for displaying vertical videos the Nexus 5X produced an image that needed to be rotated counter-clockwise during playback. The camera sensor output horizontal video which I corrected in the player.
This worked for a while until I built our iOS app and tested on more Android devices. We made a few interesting discoveries:
- On iOS an orientation can be chosen for recording through the
AVCaptureConnection.videoOrientationproperty; however, Apple warns this does not physically rotate the buffer. The video still needed a 90-degree clockwise correction in the player. - On Android, camera sensors are not consistent. Unlike the Nexus 5X it appears most devices need a clockwise correction.
- Additionally, the front camera on Android is not always consistent with the rear camera. On some older streams, this caused a brief period of upside down footage when switching between cameras.
Since our supported broadcasting devices were not consistent, we had two choices for preventing upside down video:
- Let the client know which direction it needed to rotate the video
- Rotate the video server-side.
Before exploring these solutions, let's examine how the camera captures images. Image sensors always capture light in a fixed orientation. That image is then processed to digitize it and correct for white balance and exposure to obtain the final appearance as a matrix of pixel values. This matrix is then encoded into a JPEG file to reduce the file size. The unencoded color matrix may not be in the correct orientation for display, so extra information is included in the file to specify how it should be rotated when displayed. Historically it was computationally costly for the camera to physically rotate the pixel matrix, so the operation was delegated to the image viewer. For modern video formats, something similar is done.
The problem with Loki letting the client perform rotation is that MPEG-TS files, which are standard for HLS, do not support this rotation metadata. Without the file holding the information, we would have to store rotation information in our database and update the Loki API to provide this to the app during playback. Since our streaming engine and data layer were separate pieces of software, while possible, this did not seem like the correct solution.
Since we already had to transcode all video coming in, we decided to rotate each video frame on our servers instead. This turned out to be more interesting than expected.
A Naive Approach
The Loki streaming engine first decoded video from the broadcaster before it processed it and transcoded at different resolutions. To rotate decoded frames, I first needed to understand the pixel format our decoder returned.
You may already be familiar with the RGB colorspace. In this format, every pixel has an intensity of red, green and blue. For example, a three-byte pixel 0x0000FF would represent pure blue. In this representation, each color channel takes up one byte, so every pixel takes up a total of three bytes. For video, this gets really expensive.
It turns out, as long as we keep the luminance (brightness) for every pixel we can get away with having the same chrominance (color) for each group of four pixels. This is brilliant because it means for a 1920x720 pixel frame instead of needing 4MB (1920x720 pixels x 3 bytes/pixel) to store the frame, we only need 2MB (using two chrominance bytes for every 4 pixels).
To illustrate this consider the following 6x2 pixel frame:
 Groups of pixels can share the chrominance plane and still have different "colors" as the luminance changes.
Groups of pixels can share the chrominance plane and still have different "colors" as the luminance changes.
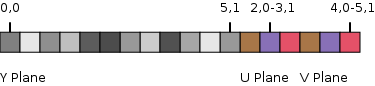 The YUV 4:2:0 data layout for a 6x2 pixel image: Each box represents a single byte. Note that both the U and V planes are needed to represent the chrominance and the colorization is meant for illustrative purposes only.
The YUV 4:2:0 data layout for a 6x2 pixel image: Each box represents a single byte. Note that both the U and V planes are needed to represent the chrominance and the colorization is meant for illustrative purposes only.
Loki's decoder returned frames in the YUV 4:2:0 color format. This format is planar meaning that it stores pixel data in three separate planes: one for luminance, followed by two for chrominance. Each chrominance plane is a quarter the size of the luminance plane. In order to rotate the video, I needed to rotate each plane individually.
Let's try the most straightforward approach for a 90-degree clockwise rotation:
This first implementation written in D consisted of two nested for loops to rotate the planes. First I rotated the luminance plane, and then since the two chrominance planes were of equal size I rotated them in the same loop. The idx variable referred to the position in the output buffer. In the second loop idx was the position in the U-plane, and I offset this by the size of the plane to refer to the same pixels in the V-plane.
uint lines = f.dim.height;
uint columns = f.dim.width;
ubyte[] channelY = f.data[0..columns*lines];
ubyte[] channelU = f.data[columns*lines..(columns+columns/4)*lines];
ubyte[] channelV = f.data[(columns+columns/4)*lines..$];
...
// Allocate a new buffer to store the rotated frame
ubyte[] newData = UByteAllocator.alloc(f.data.length);
newData.length = f.data.length;
ulong idx = 0;
// first copy y plane
for(int x=0; x<columns; ++x){
for(int y=lines-1; y>=0; --y){
newData[idx] = channelY[columns*y + x];
idx ++;
}
}
// copy u and v planes
// Notice that there are half as many columns and half
// as many rows in this loop
for(int x=0; x<columns/2; ++x){
for(int y=(lines/2)-1; y>=0; --y){
newData[idx] = channelU[columns*y/2 + x];
newData[idx+(lines*columns/4)] = channelV[columns*y/2 + x];
idx ++;
}
}
// Free old buffer and replace frame data
UByteAllocator.reap(f.data);
f.data = newData;
// now update dimensions
f.dim = f.dim.rotated90();This was not practical. I tested this method using a 16-second clip which originally took 10.26 seconds to transcode on my laptop. With the added rotation, it took 19.76 seconds to transcode. This meant there was no way the footage could be processed in real time. Live streaming would simply not work for Loki's original streaming.
After these abysmal results, I actually gave up. It wasn’t really that important at the time because we only used iOS. I even deleted the file!
Understanding Language Details
Fortunately, Linux doesn’t overwrite deleted files until the disk runs out of storage. I was able to recover my initial work using grep and knowing the name of the module:
$ sudo grep -a -C 400 -F 'FPRotate' /dev/sda8So what went wrong with the code? I recalled that D performed bounds checking on array operations so I first converted the code to use raw pointers. To illustrate this I executed the following method on a 20MB preallocated array 100 times. It took 2.38 seconds on average.
ubyte process(ref ubyte[] arr) {
auto arrPtr = arr.ptr;
for(auto i=0; i<1024*1024*20; ++i) {
if(i > 2) {
arr[i] = (arr[i-1] + arr[i-2] + 1);
}
}
return arr[$-1];
}But I knew the size of arr and did not need the compiler to confirm I was safely accessing the array. So I instead accessed it as a pointer which does not perform any bounds checking. By changing this line:
arr[i] = cast(ubyte)(arr[i-1] + arr[i-2] + 1);to
arrPtr[i] = cast(ubyte)(arrPtr[i-1] + arrPtr[i-2] + 1);I reduced the execution time to 1.57 seconds. Note that I had to make this algorithm non-trivial for demonstration, otherwise the compiler optimizes away the bounds checking anyway.
But that still wasn’t good enough. With some additional optimizations to our byte allocator, I got the video processing time down to 15.7 seconds which was still too close to 16 seconds for comfort.
Interfacing with the Machine Itself
As an electrical engineering student fascinated with low-level software and computer architecture, it was pretty natural for me to consider assembly language. Compilers are pretty good at optimization, but there are some rare cases where they can’t beat carefully crafted assembler. This was one of those exciting moments.
My suspicion was that memory access was a bottleneck in the code. Nothing could be done about moving 2MB worth of data for every frame, but I thought I could at least minimize memory access time for the few variables inside the algorithm. Looking at my D code I realized I could fit every variable into a register on AMD64 hardware. This way the only memory access would be for the buffers.
uint lines = f.dim.height;
uint columns = f.dim.width;
ubyte[] channelY = f.data[0..columns*lines];
ubyte[] channelU = f.data[columns*lines..(columns+columns/4)*lines];
ubyte[] channelV = f.data[(columns+columns/4)*lines..$];
uint strideU = columns/4; // pixels/row in U plane
...
// Allocate a new buffer to store the rotated frame
ubyte[] newDataArr = UByteAllocator.alloc(f.data.length);
newDataArr.length = f.data.length;
ubyte *newData = newDataArr.ptr;
ulong idx = 0;
// ASM Version
asm {
mov R15D, columns ; // Column count
mov R14D, lines ; // Line count
mov R13, newData ; // Pointer to newData
mov R12, channelY ; // Pointer to channelY
mov R11, channelV ; // Pointer to channelV
mov R9, idx ; // idx load
xor EAX, EAX ; // x = 0
forYPlaneOutter: ;
cmp EAX, R15D ;
jge forYPlaneOutterExit ; // Exit if x >= columns
mov EBX, R14D ;
dec EBX ; // y=lines - 1
forYPlaneInner: ;
cmp EBX, 0 ;
jl forYPlaneInnerExit ; // Exit if y < 0
mov R8D, EBX ; // y
imul R8D, R15D ; // columns*y
add R8D, EAX ; // x + columns*y
mov R8B, [R8D+R12] ; // channelY[columns*y + x] (load)
// newData[idx] = channelY[columns*y + x] :
mov [R9+R13], R8B
inc R9 ; // idx ++
dec EBX ; // y --
jmp forYPlaneInner ;
forYPlaneInnerExit: ;
inc EAX ; // x ++
jmp forYPlaneOutter ;
forYPlaneOutterExit: ;
// For the UV planes we no longer need pointer to Y
// R11 still points to channelV
mov R12, channelU ; // Pointer to channelU
movsxd qword ptr R10, strideU;
imul R10D, R14D ; // strideU * lines
mov R8D, R14D ;
shr R8D, 1 ; // lines/2
mov R14D, R15D ;
shr R14D, 1 ; // columns/2 : No longer needs lines
xor EAX, EAX ; // x=0
forUVPlaneOutter: ;
cmp EAX, R14D ;
jge forUVPlaneOutterExit ; // Exit if x >= columns/2
mov EBX, R8D ;
dec EBX ; // y=(lines/2) - 1
forUVPlaneInner: ;
cmp EBX, 0 ;
jl forUVPlaneInnerExit ; // Exit if y < 0
mov ECX, EBX ; // y
imul ECX, R15D ; // y*columns
shr ECX, 1 ; // y*columns/2
add ECX, EAX ; // x + y*columns/2
mov CL, [ECX+R12] ; // channelU[columns*y/2 + x] (load)
// newData[idx] = channelU[columns*y/2 + x] :
mov byte ptr [R9+R13], CL ;
mov ECX, EBX ; // y
imul ECX, R15D ; // y*columns
shr ECX, 1 ; // y*columns/2
add ECX, EAX ; // x + y*columns/2
mov CL, [ECX+R11] ; // channelV[columns*y/2 + x] (load)
add R9, R10 ; // idx+(strideU*lines) : Mutates idx
// newData[idx+(strideU*lines)] = channelV[columns*y/2 + x] :
mov byte ptr [R9+R13], CL ;
sub R9, R10 ; // restores idx
inc R9 ; // idx ++
dec EBX ; // y --
jmp forUVPlaneInner ;
forUVPlaneInnerExit: ;
inc EAX ; // x ++
jmp forUVPlaneOutter ;
forUVPlaneOutterExit: ;
}
// Free old buffer and replace frame data
UByteAllocator.reap(f.data);
f.data = newDataArr;
// now update dimensions
f.dim = f.dim.rotated90();The results were magical. We processed the video in 12.4 seconds, making it suitable for real-time transcoding even on my personal laptop.
If you’re looking to go assembler, there are some trade-offs to consider. First, you limit your code to only the architectures you write it for. Loki cannot run video processing on ARM chips or even 32-bit Intel chips because of this. Additionally, with inline assembler, the state of the registers must be saved and restored before and after the block. For Loki, this code only ran 30 times per second of footage, so this was a negligible expense.
When writing assembler, you’ll need to map your variables to registers and save enough registers for arithmetic. In this code I used the following variable mapping:
| Variable | Register |
|---|---|
| Columns (Count) | R15 |
| Lines (Count) | R14 |
| newData buffer pointer | R13 |
| channelY and later channelU buffer pointers | R12 |
| channelV buffer pointer | R11 |
| X | AX |
| Y | BX |
| Idx | R9 |
Notice I reused register R12 when the original mapping was no longer needed. Also, you may need to clobber a variable to work with it and make sure to restore it afterward. In this algorithm, I needed the result idx+(strideU*lines) to index into an array. But since x86 uses two operands add instructions, I had to mutate either of the operands and then restore idx by subtracting after the result was used.
; Temporarily add R10 into R9
add R9, R10
; Work with R9 (which equals original R9 + R10)
; ...
; Restore R9 by subtracting R10
sub R9, R10It takes some getting used to assembler, but once you start memorizing the instructions and have some pen and paper to track variables it can be really rewarding. Have fun!